Key Value Stores
Databases are generally divided into two categories : relational databases, and non-relational databases. Relational databases were invented in 1970 to model financial transactions [1]. A relational database (RDB) organizes data into rows identified by primary keys. Tables can reference records in other tables, using their primary keys. A primary key embedded in a foreign table is called a foreign key.
RDBs can model complex systems in the real world, including business transactions, analytics and scientific experiments. One of the advantages of RDBs is the ease of joining records in one table with records in another. Consider the data model represented by the diagram below - the Users table can be compressed by storing the name of the country and continent in a different table.
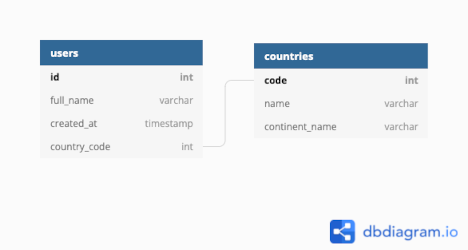
If relational databases are so versatile, what are non-relational databases and why are they useful? To answer this question, let’s start by revisting a well-known data structure.
Hash Tables
Hash tables are a data structure consisting of a key and a value. A hash table users a hash function which accepts a key as an input, and returns the address in memory where the value is stored. Compared to an array, a hash table has a better lookup time because computing the hash function, and accessing a pointer both take constant time \(O(1)\).
The most basic implementation of a key value store is a hash table. For example, you might have a data store, users, which stores user information. Each user is uniquely identified by a key, user_id. The hash function maps the key user_id to a block of bytes in memory. The block of bytes is used to store the value, in this case, the name of the user.
Now let’s say you want to overwrite the names of one of the users. At first glance, updating the block of memory directly seems like the most sensible option - you could look up the user with a user_id = 1 and replace the name which is stored at that address.
However, this approach has several disadvantages. Consider the case when a user tries to update the database, and the database crashes during the middle of the write. The blocks in memory in this case will contain part of the old value, and part of the new value. Concurrency also becomes difficult - how does the database handle the case when two users try to update the same value at the same time? [3]
Databases often solve this problem using transaction logs. Write operations are appended to a log, and records which appear later in the log take precedence. If two users update the same value, the transaction log will contain two records with updates to that value.
SSTables
SSTables are a special implementation of transaction logs. Originally introduced by Google [2], SSTables are a core component of non-relational DBs including Google BigTable, Amazon DynamoDB and Apache Cassandra.
An SSTable is a segment of a transaction log which is sorted by key. This data structure offers several performance advantages over an unsorted log. First, it is much faster to combine sorted log segments as opposed to unsorted segments. The combination algorithm is similar to the merge sort algorithm. Second, since the keys are sorted you can store a sparse index and infer the location of keys which are not contained within the index.
Now that we have taken a look at the data structures which power non-relational databases, let’s answer a different and perhaps more important question. Why do people use NoSQL databases?
Replication
Let’s say your company has gotten a lot of traction in Europe, and you need to reduce the time of requests which are made by the European user base. In order to support low latency, you want requests in Europe to be routed to a data center in Europe. You need to replicate your data across different machines.
You might start by writing a script to copy data from your data center in North America to your data center in Europe. However, consider the following scenario : a user in North America and a user in Europe try to update the same piece of data, at the same time. How can you replicate a database, and guarantee consistency?
The long answer is that there is always a tradeoff between consistency and availability. On the one hand, you can have a totally consistent system, meaning clients always read the same values when accessing the database at the same time. On the other, you can have a totally available system meaning that the system is available for all clients in the event of a node outage.
Dynamo and Cassandra implement eventual consistency - clients will always have access to the system, but clients may read different values when accessing the DB at the same time [4]. For most applications, this tradeoff is acceptable. One notable exception might be financial applications where it is critical that all users have access to consistent data.
Returning to our original question - non-relational databases are useful when you need to replicate data across a distributed system. If you were to implement replication with a SQL database you would need to write code which enforces a consistency model. Fortunately, there are plenty of NoSQL databases which have already solved this problem.
Sharding
Let’s say we are building Youtube, and we need to create a data store for user videos. To start, you might store all the videos in a single databse videos, which is hosted on a single machine. As you scale your user base, you will quickly run out of storage space on your machine.
To solve the problem, you purchase n machines, partition the videos database into n segments, and store one segment on each machine. This works for a while, but what happens when one of the machines goes down?
Now, you start replicating each partition across 3 different machines. When a node experiences an outage, you can reference one of the backups. This preserves the availability of data stored in your system. Handling node outages causes the system to grow in complexity - we also need nodes to be aware of which nodes are alive and which are dead.
Some of these distributed system problems are solved by non-relational databases. To solve the sharding problem with a relational database, you might need to write code which coordinates communication between nodes. Fortunately, distributed communication is already implemented in databases like BigTable and Cassandra.
Conclusion
We have examined the data structures which power non-relational databases - specifically, hash tables and SSTables. We took a look at some problems which engineers face when building a distributed data store, and also some of the reasons an engineer might choose to use a non-relational database. This article hardly scratches the surface - I encourage any interested reader to continue their research!
References
- [1] E.F. Codd. A Relational Model of Data for Large Shared Data Banks.
- [2] Google. BigTable, A Distributed Storage System for Structured Data.
- [3] Martin Kleppmann. Designing Data Intensive Applications, Chapter 3.
- [4] Alex Wu. System Design Interview.